
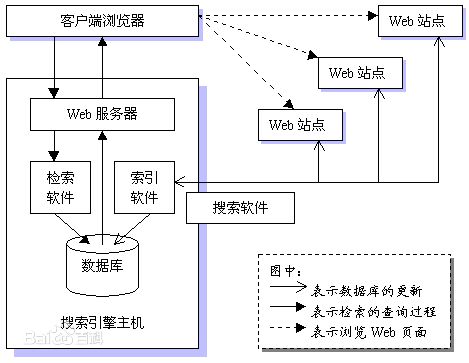
搜索引擎原理
查看了一下搜索引擎的原理,大概理解了一下(取自百度百科)。
原理:爬行和抓取、建立索引等
搜索引擎
通常指的是收集了万维网上几千万到几十亿个网页并对网页中的每一个词(即关键词)进行索引,建立索引数据库的全文搜索引擎。
使用
当用户查找某个关键词的时候,所有在页面内容中包含了该关键词的网页都将作为搜索结果被搜出来。
排序展示
在经过复杂的算法进行排序(或者包含商业化的竞价排名、商业推广、或者广告)后,这些结果将按照与搜索关键词的相关度高低(或与相关度毫无关系),依次排列。
索引数据库
在搜索引擎的后台,有一些用于搜集网页信息的程序。所收集的信息一般是能表明网站内容(包括网页本身、网页的URL地址、构成网页的代码以及进出网页的连接)的关键词或者短语。接着将这些信息的索引存放到数据库中。
工作原理
爬行和抓取
所以跟踪网页链接是搜索引擎蜘蛛(Spider)发现新网址的最基本的方法。
搜索引擎派出一个能够在网上发现新网页并抓文件的程序,这个程序通常称之为蜘蛛(Spider):
已知数据库 ——> 爬虫爬互联网外链 ——> 从一个网站到另一个,访问更多网页(爬行) ——> 新网址存入数据库
建立索引
蜘蛛抓取页面文件 ——> 分析、分解 ——> 建立索引存入数据库
搜索词处理
用户输入关键词 ——> 点击搜索 ——> 搜索引擎处理关键词,判断是否整合搜索,是否有拼写错误
排序
关键词处理后 ——> 从索引数据库中找出所有包含搜索词的网页 ——> 排序算法计算排序 ——> 返回搜索页面结果
SEO的配合很重要
数据结构
倒排文件,用记录的非主属性(副健)来查找记录而组织的文件,即次索引
全文搜索引擎(自动)
搜索引擎自动搜集信息
1、定期搜索
定期主动派出“蜘蛛”程序,对一定IP地址范围内的互联网站进行检索,一旦发现新的网站,自动提取网站的信息和网址加入自己的数据库。
2、提交网站搜索
网站拥有者主动向搜索引擎提交网址,搜索引擎一定时间内定向向该网站排出蜘蛛程序,扫描网站,录入数据库
目录索引(人工)
依赖于手工操作,目录编辑人员会亲自浏览用户提交的网站,审核评判之后归类
元搜索引擎
元搜索引擎不是一种独立的搜索引擎,它最显著的特点是没有自己的资源索引数据库。
用户搜索 ——> 同时在其他多个搜索引擎中进行搜索 ——> 并将其他搜索引擎的检索结果经过处理后返回给用户